This article is a follow-up on my previous presentation located here. The previous case study had analyzed how query rewrite would occur in a simple star schema with one fact table and two dimension tables, when both dimensions were used to aggregate the fact table data. It used a materialized view, which contained data aggregated along both dimensions, at the lowest level in each dimension, above the grain level. Subsequent aggregations which were requested against the “detail tables” at higher levels along those dimensions, were rewritten by the oracle optimizer, such that to make use of the pre-aggregated data in the materialized view.
A typical situation which is often encountered in a star-schema Data Warehouse, has to do with users formulating SQL queries that contain a subset of the relational dimensions which are linked to the fact table. If the materialized view used for query rewrite (see above) has been pre-aggregated at lower levels along each of those dimensions, then the following question arises: Would query rewrite still occur, and would it use that same MV, if we used only a subset of dimensions joined to the fact table in our SQL query?
Here is a brief description of the scenario above: we have fact table Fact_T1 containing data and FK’s to dimension tables Dim_T1, Dim_T2, …., Dim_Tn. We also have a materialized view MV_1_n which contains pre-aggregated data at lower levels above the grain for each dimension Dim_1, Dim_2, …., Dim_n. Various users create all kinds of SQL queries, some of which link fact table Fact_T1 to arbitrary subsets of dimensions, let’s say for example Dim_T1, Dim_T2, and Dim_T3. We need query rewrite to occur under these specific circumstances, and we need the data returned to be accurate.
We shall simplify the scenario mentioned above (one fact table and “n” dimension tables), to the simple scenario from the previous article (one fact table and 2 dimension tables).
My intuition is telling me that query rewrite should still occur in such a scenario. Let’s see how the oracle optimizer behaves in a situation like this one, based on the previous case study which was presented here.
Let’s look at the simple star schema configuration with one fact table and two dimension tables as described in the previous article, and shown below in Figure 1:
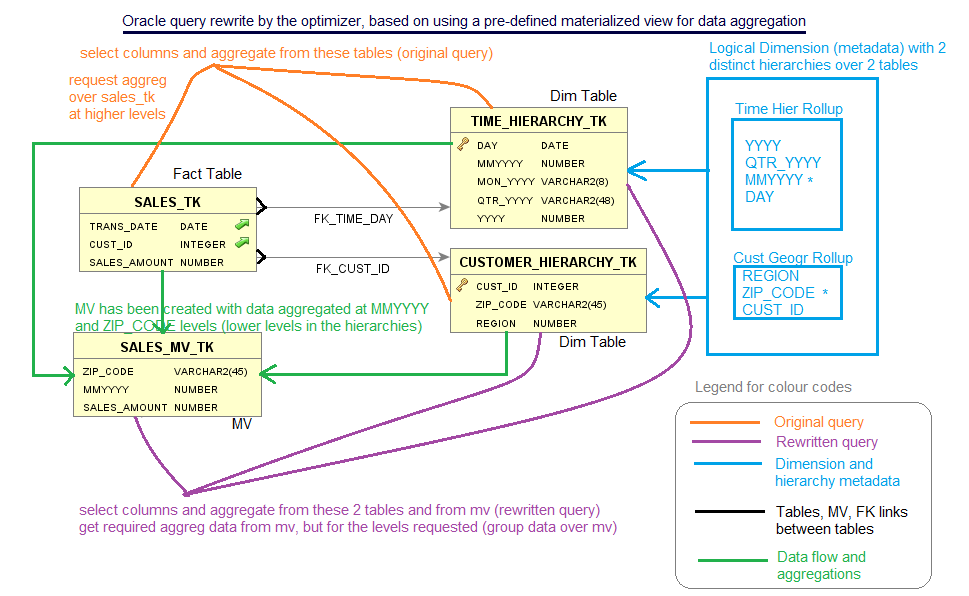
Figure 1
Let’s set the session parameters as follows, with "query rewrite enabled” set to enabled, and “query rewrite integrity” set to trusted:
ALTER SESSION SET query_rewrite_enabled = TRUE;
ALTER SESSION SET query_rewrite_integrity = TRUSTED ;
Let’s use the following SQL query (Q1) below:
SELECT
SUM(SALES_AMOUNT), TIME_HIERARCHY_TK.QTR_YYYY
FROM SALES_TK, TIME_HIERARCHY_TK
WHERE SALES_TK.TRANS_DATE = TIME_HIERARCHY_TK.DAY
GROUP BY TIME_HIERARCHY_TK.QTR_YYYY;
Below we see the execution plan:

Figure 2
The execution plan indicates that no rewrite to the MV has occurred, although the data is there, the MV is enabled for query rewrite, and the session parameters are set accordingly.
Why did query rewrite occur when we aggregated along both dimensions, but not when we aggregate along one of them ?
For now, I do not have an answer to the second part of this question. However, let’s see if the data in the MV would support aggregating along one of the dimensions, regardless of the execution plan. As a note, the MV has been built by aggregating fact data along two dimensions.
First, the result of the query (Q1) is shown below, after a full table scan of the detail tables (no MV access):
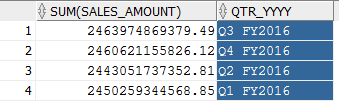
Figure 3
Now, let’s write a SQL query (Q2) that would access the MV data, aggregated along one dimension by TIME_HIERARCHY_TK.QTR_YYYY. This is similar to the rewritten query for aggregating along both dimensions, except it only groups along one of those dimensions:
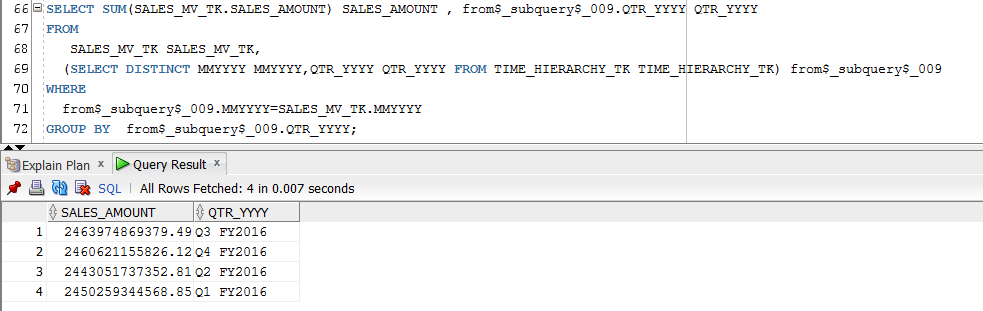
Figure 4
Let’s see now if there is a difference in the data sets returned by SQL queries (Q1) and (Q2). We will look at (Q1) – (Q2) and at (Q2) – (Q1), as shown below:
We see below that (Q1) – (Q2) returns an empty data set:
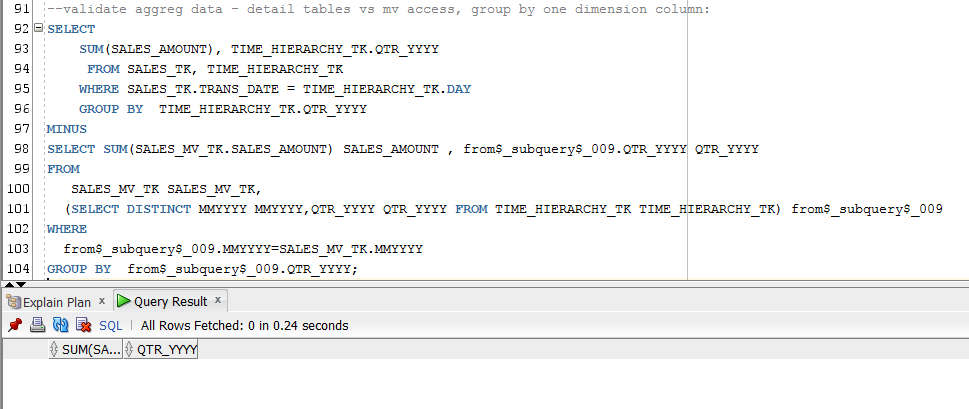
Figure 5
We see below that (Q2) – (Q1) also returns an empty data set:
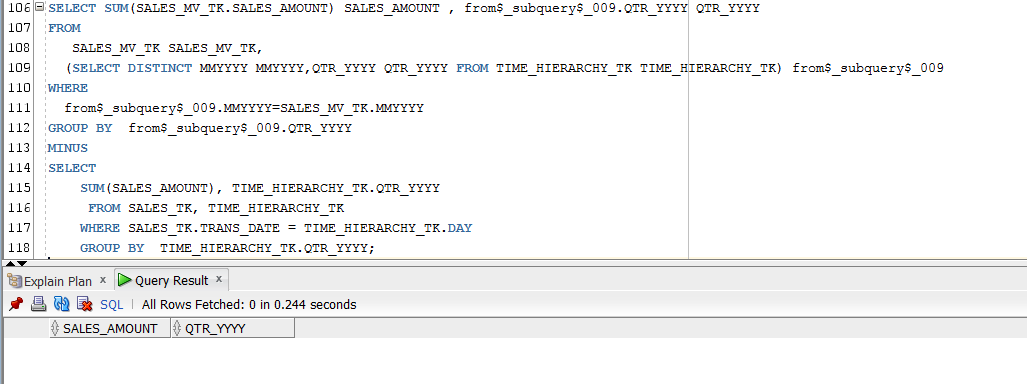
Figure 6
Therefore, the result sets returned by queries (Q1) and (Q2) are identical. So, why is the oracle optimizer not taking advantage of the pre-aggregated MV, when using only one dimension ?
Well, let’s look at the actual message returned by the oracle optimizer when it tries to re-write this SQL query:
set serveroutput on size 900000;
declare
v_code NUMBER;
v_errm VARCHAR2(4000);
sql_stmt varchar2(500) :=
'SELECT
SUM(SALES_AMOUNT), TIME_HIERARCHY_TK.QTR_YYYY
FROM SALES_TK, TIME_HIERARCHY_TK
WHERE SALES_TK.TRANS_DATE = TIME_HIERARCHY_TK.DAY
GROUP BY TIME_HIERARCHY_TK.QTR_YYYY';
begin
dbms_output.enable;
sys.xrw(mv_list => null, command_list => 'REWRITTEN_TXT', querytxt => sql_stmt);
EXCEPTION
WHEN OTHERS THEN
v_code := SQLCODE;
v_errm := SUBSTR(SQLERRM, 1 , 3999);
DBMS_OUTPUT.PUT_LINE('Exception: ERRCODE=' || v_code || ' ERRMSG=' || v_errm);
DBMS_OUTPUT.PUT_LINE('Call Stack=[' || DBMS_UTILITY.FORMAT_ERROR_STACK || ']');
DBMS_OUTPUT.PUT_LINE('Error Stack=[' || DBMS_UTILITY.FORMAT_ERROR_BACKTRACE || ']');
ROLLBACK;
RAISE;
end;
The message is shown below:

Figure 7
The text message is not very explicit in telling us what we need to do, to make the optimizer rewrite the SQL query.
I did some research online, read some more oracle documentation, perused several discussion forums about this subject matter, and still I could not find a solution.
Some of the contributors to discussions in certain online forums were of the opinion that this is the way oracle query rewrite behaves, that it simply is not possible to get the query rewritten when a subset of dimensions were being used. They themselves had tried and someone else had told them it couldn’t be done.
To me, it didn’t make much sense, since the data was there, as verified above with queries (Q1) and (Q2). The problem is, that the oracle optimizer needs some additional information in such a situation, probably because the SQL text of the “subset query” no longer matches the SQL text of the MV definition (see this page for a brief description of the query rewrite methods).
After some more reading, my attention somehow got focused on constraints and the role they play in enabling query rewrite. So, I tried a few things:
- I added
NOT NULLconstraints on the FK columns in the fact table SALES_TK - I dropped the materialized view SALES_MV_TK, and I re-created it by using the constraint clauses
USING TRUSTED CONSTRAINTSandENABLE QUERY REWRITE - I added
NOT NULLconstraints on columns ZIP_CODE and MMYYYY in table SALES_MV_TK (which is the underlying table of the materialized view with the same name) - I added a
PRIMARY KEY (ZIP_CODE, MMYYYY) RELY DISABLE NOVALIDATEconstraint on table SALES_MV_TK (which is the underlying table of the materialized view with the same name). This is very important, since this PK constraint is needed for query rewrite to occur when using subsets of dimensions.
In order to test these changes “along the way”, I made a copy of fact table SALES_TK and named it SALES_TK_C, and added the new constraints to the new table. I did the same for the materialized view SALES_MV_TK – I named the new version SALES_MV_TK_C, I changed the definition to base it on the new fact table SALES_TK_C, and I added the new constraints to it and to its’ underlying table.
Now, let’s see how the oracle optimizer chooses to process a SQL query that aggregates along one dimension only:
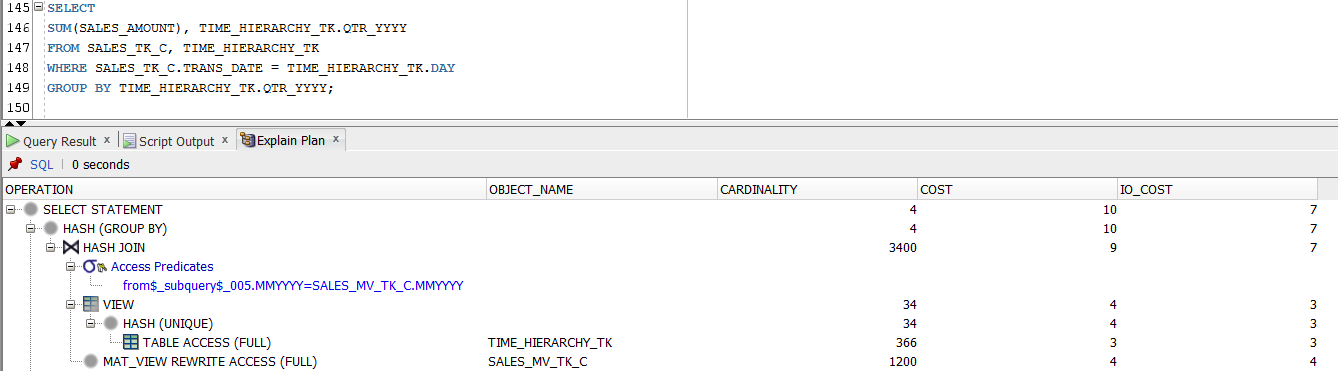
Figure 8
Yes ! It did rewrite the query to access the MV, even though only one dimension was used in the original SQL statement !
Just to have more insight into the rewrite process, let’s see what the optimizer says about rewriting a SQL query with one dimension:
set serveroutput on size 900000;
declare
v_code NUMBER;
v_errm VARCHAR2(4000);
sql_stmt varchar2(500) :=
'SELECT
SUM(SALES_AMOUNT), TIME_HIERARCHY_TK.QTR_YYYY
FROM SALES_TK_C, TIME_HIERARCHY_TK
WHERE SALES_TK_C.TRANS_DATE = TIME_HIERARCHY_TK.DAY
GROUP BY TIME_HIERARCHY_TK.QTR_YYYY';
begin
dbms_output.enable;
sys.xrw(mv_list => null, command_list => 'REWRITTEN_TXT', querytxt => sql_stmt);
EXCEPTION
WHEN OTHERS THEN
v_code := SQLCODE;
v_errm := SUBSTR(SQLERRM, 1 , 3999);
DBMS_OUTPUT.PUT_LINE('Exception: ERRCODE=' || v_code || ' ERRMSG=' || v_errm);
DBMS_OUTPUT.PUT_LINE('Call Stack=[' || DBMS_UTILITY.FORMAT_ERROR_STACK || ']');
DBMS_OUTPUT.PUT_LINE('Error Stack=[' || DBMS_UTILITY.FORMAT_ERROR_BACKTRACE || ']');
ROLLBACK;
RAISE;
end;
Below we see the output message:
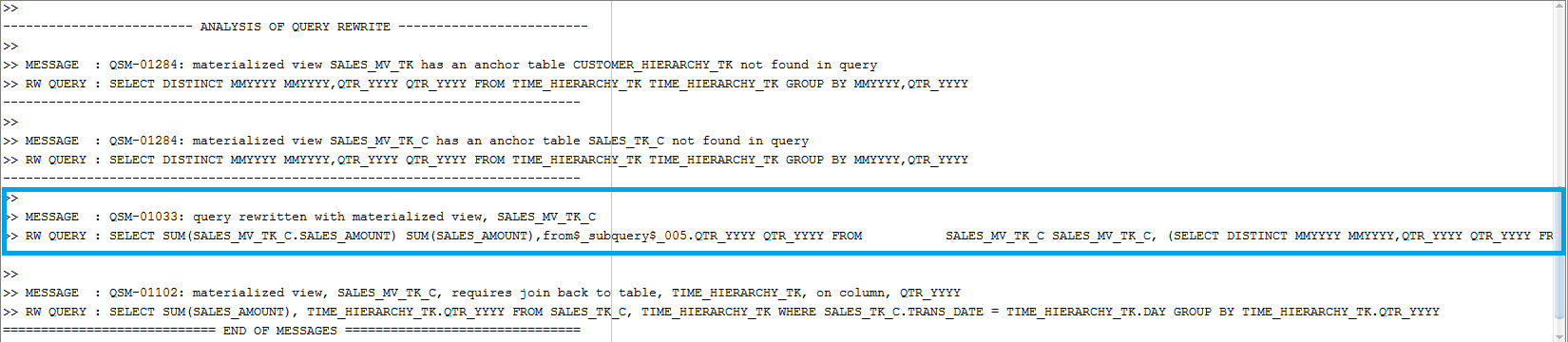
Figure 9
The original SQL query is listed below (I now use SALES_TK_C instead of SALES_TK, in order to take advantage of the additional constraints added):
SELECT
SUM(SALES_AMOUNT), TIME_HIERARCHY_TK.QTR_YYYY
FROM
SALES_TK_C, TIME_HIERARCHY_TK
WHERE SALES_TK_C.TRANS_DATE = TIME_HIERARCHY_TK.DAY
GROUP BY TIME_HIERARCHY_TK.QTR_YYYY;
The re-written SQL query is listed below:
SELECT
SUM(SALES_MV_TK_C.SALES_AMOUNT) SUM(SALES_AMOUNT),
from$_subquery$_005.QTR_YYYY QTR_YYYY
FROM
SALES_MV_TK_C SALES_MV_TK_C,
(SELECT DISTINCT MMYYYY MMYYYY,QTR_YYYY QTR_YYYY FROM TIME_HIERARCHY_TK TIME_HIERARCHY_TK) from$_subquery$_005
WHERE from$_subquery$_005.MMYYYY=SALES_MV_TK_C.MMYYYY
GROUP BY from$_subquery$_005.QTR_YYYY;
To summarize: it is possible to benefit from query rewrite to a materialized view defined with data aggregated by all dimensions of a star schema, even when the SQL query joins only a subset of those dimensions to the fact table.