– In addition to the requirement that query rewrite be enabled by appropriately setting the two database parameters mentioned previously (query_rewrite_enabled and query_rewrite_integrity), there are a number of additional checks that the data, the user query and the pre-defined “mv”(s) must pass, in order for query rewrite to occur. These validation checks are :
- Join compatibility check
- Data sufficiency check
- Grouping compatibility check
- Aggregate computability check
– 1. Join compatibility check means that the joins in the user query are compared against the joins in the “mv”(s). There are 3 types of joins in this regard:
- (1.1) Common joins that occur both in the query and in the “mv”
- (1.2) Delta joins that occur in the query, but not in the “mv”
- (1.3) Delta joins that occur in the “mv”, but not in the query
– If any one or more of these joins are present, then the optimizer verifies that the existing constraints on the details tables and on the “mv”, as well as the structure of the “mv”, can guarantee a deterministic result by way of query rewrite. It tries to infer new joins from the existing metadata, in order to take advantage of the pre-defined “mv”. In scenario (1.3), all “mv” delta joins are required to be lossless and non-duplicating with respect to the result of common joins (1.1).
– 2. Data sufficiency check means that the optimizer tries to determine if the column data required by the user query, can be obtained from a “mv”.
– 3. Grouping compatibility check is done only when the user query and the “mv”, both contain a “group by” clause. First, the optimizer checks if the grouping of data requested by the query, is the same as the grouping of data in the “mv”. If the “mv” groups data on additional columns than in the user query, then query rewrite can re-aggregate the data in the “mv” by the grouping columns of the user query, in order to generate the expected result.
– 4. Aggregate computability check is done only when the user query and the “mv”, both contain aggregates. The optimizer determines whether the aggregates requested by the user query, can be derived or calculated from the aggregate(s) stored in the “mv”. Furthermore, if the previous check for “grouping compatibility” determined that a rollup of the aggregates from the “mv” is required, then the optimizer determines if it is possible to roll up each of the aggregates requested in the user query, by using the aggregates from the “mv”.
Case study: A simple star schema with one fact and two dimension tables
Let’s try to implement the concept of query rewrite, in the case of a simple star schema, that consists of a fact table, which is linked to two dimension tables via FK relationships (see Figure 5 below):
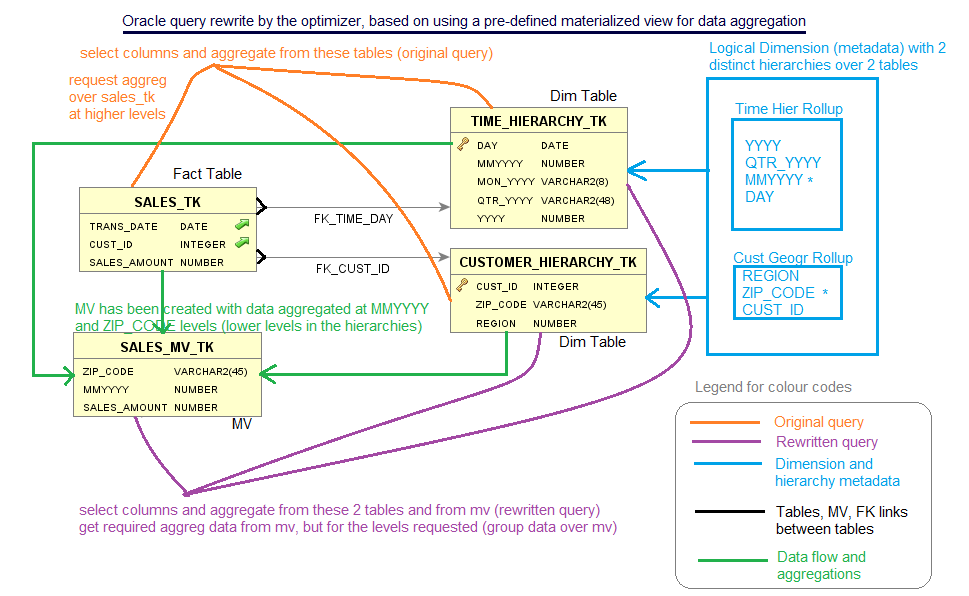
Figure 5
I will explain a bit later the meaning of the various symbols in Figure 5. For now, let’s consider a simple aggregation query listed in Figure 6, which would run against the tables from Figure 5:
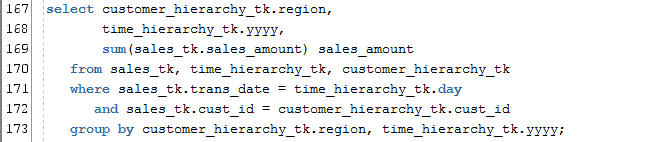
Figure 6
Let us presume that there are no indexes yet created on any of the 3 tables in Figure 5, and that query rewrite is disabled. Let’s see what the Oracle optimizer would do in order to retrieve the information requested.
Figure 7 below displays the execution plan, as shown by the Oracle SQL Developer GUI tool, for the SQL statement from Figure 6:
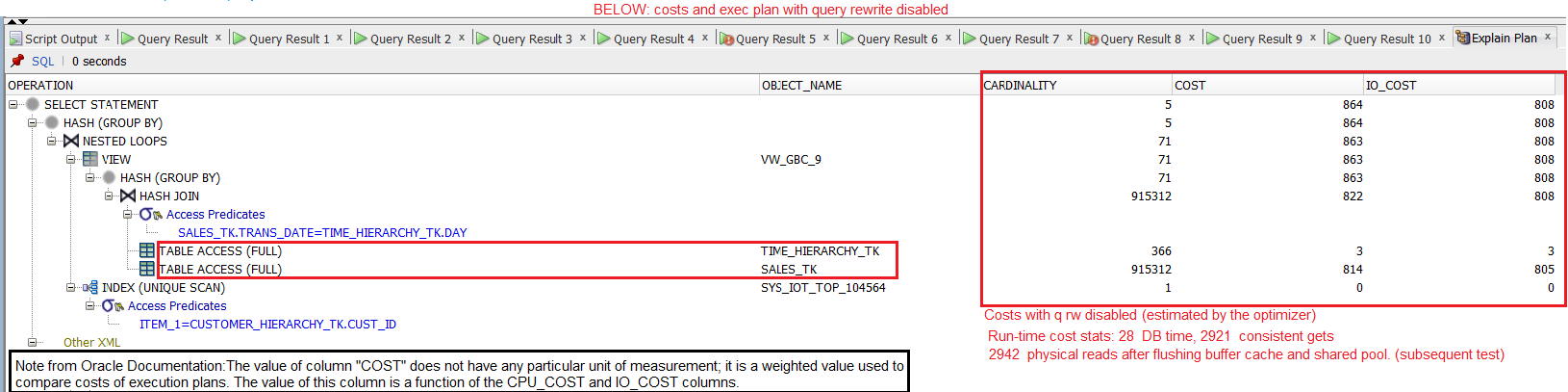
Figure 7
Figure 8 below shows the execution plan, obtained via explain plan in SQL Plus, for the SQL statement from Figure 6:
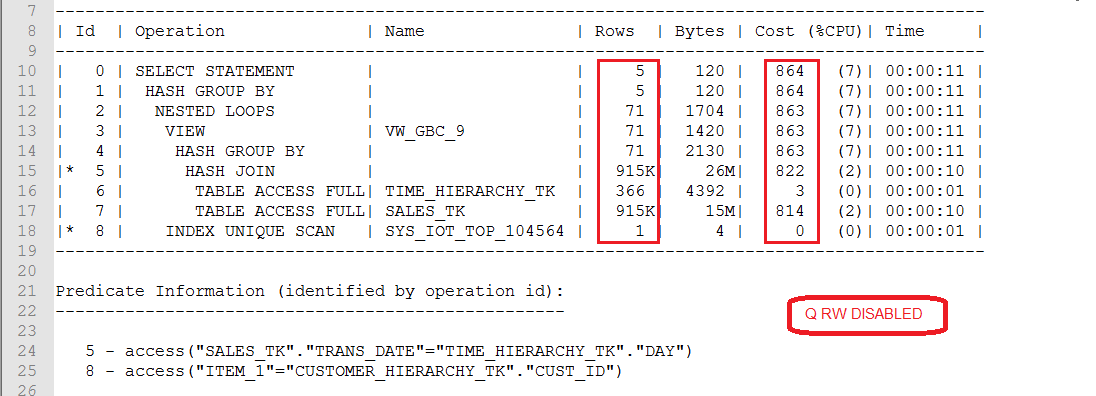
Figure 8
We can see that, when calculating sum(sales_tk.sales_amount), the oracle optimizer does a full-table scan on the fact table, in order to group the fact data by the highest levels in the two joined dimension tables.
Now, let’s try to improve the execution plan and performance for the query shown in Figure 6. We will be using dimensions, hierarchies and a materialized view, in order to allow the oracle optimizer to choose an execution plan which would make use of query rewrite to the materialized view.
The query rewrite method used by oracle in this case is “rollup using a dimension”.
The pre-requisite conditions which are necessary for query rewrite to occur in our case study, are listed below:
- Declare dimension(s) and related hierarchies over the existing dimension tables
- Alter session (or system) parameters to allow or enable query rewrite
- Create materialized view with query rewrite enabled
Now, let’s go over each of the conditions mentioned above.
– We can enable the pre-requisite condition #1 by declaring relational dimension(s) and related hierarchies over the existing dimension tables, as shown in Figure 9 below:
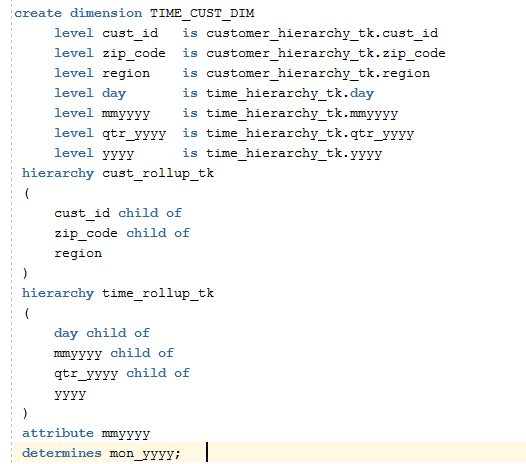
Figure 9
Now, let’s verify the pre-requisite condition #1 (dimension(s) and hierarchies have been created):
select * from user_dimensions;

Figure 10
We should also verify that the hierarchies have been created, as shown below:
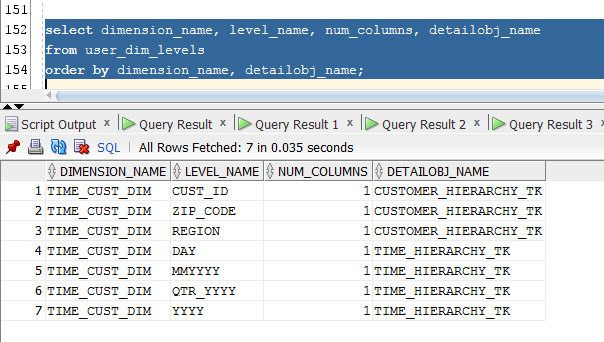
Figure 11